Overview
SpookyStuff is a scalable and lightweight query engine for web scraping/data mashup/acceptance QA. The goal is to allow remote resources to be linked and queried like a relational database. Its currently implementation is influenced by Spark SQL and Machine Learning Pipeline.
SpookyStuff is the fastest big data collection engine in history, with a speed record of searching 330404 terms in an hour with 300 browsers.
Powered by
![]()
![]()
![]()


![]()

![]()
Installation
Main article: Installation
Why so complex? All you need is is a single library in your Java/Scala classpath:
groupId: com.tribbloids.spookystuff
artifactId: spookystuff-assembly_2.10
version: 0.3.2
You have 3 options: download it, build it or let a dependency manager (Apache Maven, sbt, Gradle etc.) do it for you.
Direct Download
| Stable (0.3.2) | Nightly (0.3.3-SNAPSHOT) | |
|---|---|---|
| Library | Download .jar | Download .jar |
| Bundled with Spark 1.5.1 | Download .zip | Download .zip |
| Bundled with Spark 1.4.1 | Download .zip | Download .zip |
| Bundled with Spark 1.3.1 | Download .zip | Download .zip |
This pre-built JAR/bundle provide full functionality out-of-the-box, however you need a Apache Spark installation first (including integrated Spark environment, e.g. Notebooks in databricks™ Cloud or Apache Zeppelin). If you haven’t done so, please refer to Apache Spark installation Guide or Integration Section.
As a Dependency
if you want to use SpookyStuff as a library in your source code, the easiest way is to let your dependency manager (e.g. Apache Maven, sbt, gradle) to download it automatically from the Maven Central Repository, by adding the following artifact reference into your build definition:
<dependency>
<groupId>com.tribbloids.spookystuff</groupId>
<artifactId>spookystuff-core_2.10</artifactId>
<version>0.3.2</version>
</dependency>libraryDependencies += "com.tribbloids.spookystuff" % "spookystuff-core_2.10" % "0.3.2"'com.tribbloids.spookystuff:spookystuff-core_2.10:0.3.2'[com.tribbloids.spookystuff/spookystuff-core_2.10 "0.3.2"]Many integrated Spark environments (e.g. Spark-Shell, databricks™ Cloud or Apache Zeppelin) has built-in dependency manager, which makes deployment much easier by eliminating the necessity of manual download. This is again covered in Integration Section.
Sourcecode Download
If you are good with programming and prefer to build it from scratch:
| Stable (0.3.2) | Nightly (0.3.3-SNAPSHOT) |
|---|---|
| Download .zip | Download .zip |
| Download .tar.gz | Download .tar.gz |
For how to build from sourcecode, please refer to Build Section.
Quick Start
First, make sure Spark is working under your favorite IDE/REPL:
import org.apache.spark.SparkContext
import org.apache.spark.SparkConf
// you don't need these if SparkContext has been initialized
// val conf = new SparkConf().setAppName("SpookyStuff example").setMaster("local[*]")
// val sc = new SparkContext(conf)
assert(sc.parallelize(1 to 100).reduce(_ + _) == 5050)Next, import and initialize a SpookyContext (this is the entry point of all language-integrated queries, much like SQLContext for Spark SQL):
import com.tribbloids.spookystuff.actions._
import com.tribbloids.spookystuff.dsl._
//this is the entry point of all queries & configurations
val spooky = new com.tribbloids.spookystuff.SpookyContext.SpookyContext(sc)
import spooky.dsl._From this point you can run queries on public datasets immediately. The following is a minimalistic showcase on cross-site “join”, one of the 5 main clauses:
spooky.wget("https://news.google.com/?output=rss&q=barack%20obama"
).join(S"item title".texts)(
Wget(x"http://api.mymemory.translated.net/get?q=${'A}&langpair=en|fr")
)('A ~ 'title, S"translatedText".text ~ 'translated).toDF()You will get a list of titles of English news about BHO and their respective french translations:
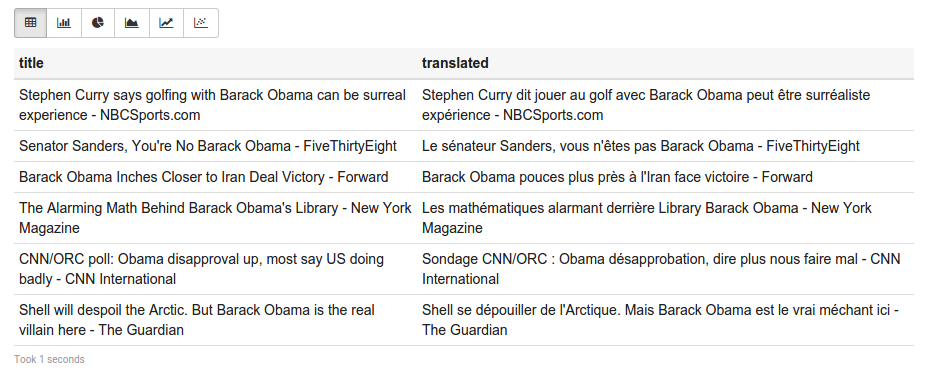
For more information on query syntax and usage, please go to Query Guide.
Web Caching
You may already notice that repeatedly running a query takes much less time than running it for the first time. this is because all web resources are cached: cached resources are loaded directly from a file directory (can be on any Hadoop-supported file system, namely HDD, HDFS, Amazon S3 and Tachyon etc.) if they haven’t expired. Unlike browsers or most search engines, SpookyStuff also caches dynamic and script-generated contents.
RDD cache is enabled by default to facilitate repeated data wrangling and dry run. To disable it, simply set spooky.conf.cacheRead = false or set spooky.conf.pageExpireAfter to a very small duration:
import scala.concurrent.duration._
spooky.conf.cacheRead = false // OR
spooky.conf.pageExpireAfter = 1.minuteHowever, before you run a query, it is recommended to point the web cache directory to a publicly-accessible, high-available storage URL (e.g. starting with hdfs:// or s3n://). Otherwise SpookyStuff will use {Java-working-directory}/temp/cache on local file system by default, which means if your query is running on a cluster, it will have a chance not able to use an already cached resource because it’s on another machine. This directory can be set by spooky.conf.dirs.cache, which affects execution of all queries derived from it:
spooky.conf.dirs.cache = "hdfs://spooky-cache"Or you can override the default web cache directory globally by setting spooky.dirs.cache system property in your Java option:
- if your query is launched from a standalone Java application:
-Dspooky.dirs.cache=hdfs://spooky-cache- OR, if your query is launched by spark-submit.sh
--conf spooky.dirs.cache=hdfs://spooky-cacheFor more performance optimization options, please go to Configuration Section.
Scaling
SpookyStuff is optimized for running on Spark cluster mode, which accelerates execution by parallelizing over multiple machine’s processing power and network bandwidth.
It should be noted that despite being able to scale up to hundreds of nodes, SpookyStuff can only approximate linear speed gain (speed proportional to parallelism) if there is no other bottleneck, namely, your concurrent access should be smoothly handled by the web services being queried (e.g. brokered by a CDN or load balancer) and your cluster’s network topology. Otherwise blindly increasing the size of your cluster will only yield diminishing return. Please refer to Scaling Section for more recommended options on cluster mode.
Performance
Profiling
SpookyStuff has a metric system based on Spark’s Accumulator, which can be accessed with spooky.metrics:
println(rows.spooky.metrics.toJSON)By default each query keep track of its own metric, if you would like to have all metrics of queries from the same SpookyContext to be aggregated, simply set spooky.conf.shareMetrics = true.
How to contribute
-
Issue Tracker: https://github.com/tribbloid/spookystuff/issues
-
GitHub Repository: https://github.com/tribbloid/spookystuff
-
Mailing list: Missing
License
Copyright © 2014 by Peng Cheng @tribbloid, Sandeep Singh @techaddict, Terry Lin @ithinkicancode, Long Yao @l2yao and contributors.
Supported by tribbloids®
Published under ASF License v2.0.